SMC Newsletter: Jan-Feb 2025
SMC Domain Outage and Fix Our domain smc.org.in [https://smc.org.in/en/
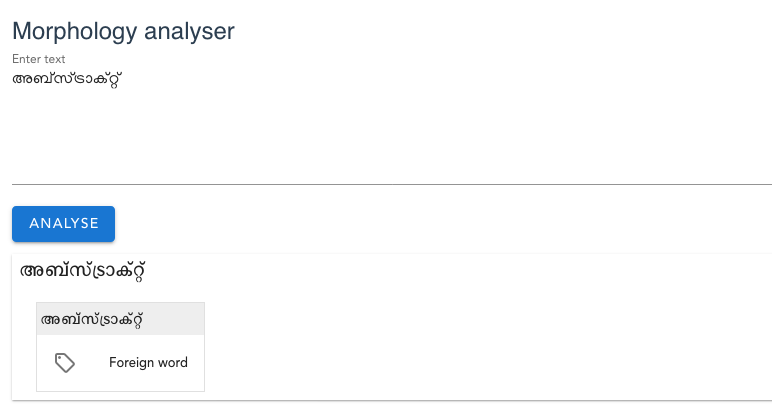
The test corpus for Malayalam Morphological analysis has many foreign words. They are either written in a non-Malayalam script or written in Malayalam. For example, “ഇലക്ട്രിസിറ്റി”, “ഡോക്സ്”, “ഇന്റർമീഡിയറ്റ്”, “അബ്സ്ട്രാക്റ്റ്”, “ഇല്ലസ്ടേഷൻ”, “ഇല്ലിറ്ററേറ്റ്”, “റെക്കോർഡ്”, “procrastination”, “唐宸禹” - These are all foreign words and it is useless to analyse them using mlmorph. Since mlmorph works based on a root word lexicon, it is practically impossible to have them in lexicon. So there should be a way to identify the words easily and tag them as FW - Foreign word Part of speech. The presence of these foreign words also distorts the coverage statistics of mlmorph. A good part of the test corpus is Malayalam wikipedia corpus and it has so many foreign words when the article is about foreign places or people.
For words written in non-Malayalam script, it is quite easy. But it is a tricky problem if the words are transliterated to Malayalam. Even for humans, it is not possible to accurately say one word is foreign or not. We usually use some patterns in the pronunciation to guess it and we base that guess from our understanding of known patterns in Malayalam. So, if we want to write a program to detect foreign words, we can try some of these patterns, but still does not guarantee a 100% accuracy. But I think that is acceptable considering language is not something you can achieve 100% accuracy always.
So I wrote a very simple python script with all known pattens that can be attributed to a non-Malayalam word and integrated with mlmorph. I could write these patterns in the FST system of mlmorph, but I wanted the flexibility of conditionally using this foreign word detection system. There are two reasons for this. First and most important one is, some foreign words get infused to the language and after few years they become part of common vocabulary. So the mlmorph lexicon has a collection of such words that originated from Latin and Sanskrit. The words we borrowed from English will follow the same inflection pattern of native Malayalam words(Examples: ബഞ്ച്, ബഞ്ചിൽ, ബസ്സിന്റെ, ബോക്സിലുള്ള). Sanskrit originated words will follow most of the inflection and agglutination rules, but there are exceptions. The foreign word detection should only be a fallback process in mlmorph analysis because of this. Secondly, when mlmorph is used for spelling correction suggestions, I should not suggest foreign words with these patterns.
This is part of mlmorph version 1.2.2 and you can try it in the collab notebook.
The API is as follows:
from mlmorph import foreign_word_detector
words = ["ഇലക്ട്രിസിറ്റി", "ഏതാണെന്ന്", "ഡോക്സ്", "ഇന്റർമീഡിയറ്റ്", "അബ്സ്ട്രാക്റ്റ്", "ഇല്ലസ്ടേഷൻ", "ഇല്ലിറ്ററേറ്റ്", "റെക്കോർഡ്", "procrastination", "唐宸禹"]
for word in words:
if foreign_word_detector.check_foreign_word(word) == 1:
print(word)
This will print
ഇലക്ട്രിസിറ്റി
ഡോക്സ്
ഇന്റർമീഡിയറ്റ്
അബ്സ്ട്രാക്റ്റ്
ഇല്ലസ്ടേഷൻ
ഇല്ലിറ്ററേറ്റ്
റെക്കോർഡ്
procrastination
唐宸禹
mlmorph CLI tool has a new option to check for foregin words- mlmorph -f.
To evaluate this system, I gave the borrowed word lexicon of mlmorph to foreign word detection and it detected 60% of the words as foreign words.
cat lexicon/english-borrowed.lex | wc -l
1309
cat lexicon/english-borrowed.lex | mlmorph -f | awk '{ if($2 == 1) { print $1 }}' | wc -l
793
echo "(793/1309)*100" | bc -l
60.58059587471352177200
The integration of foreign word detection system, gave a 12% increase in the words coverage for mlmorph. In the 14,00,000 word in test corpus(which is non curated collection of text from Malayalam wikipedia and other websites), it helped to increase coverage from 45% to 57%.
But if the corpus is non-wikipedia content, and have less foreign words, the coverage is 80% and above as you can see from the coverage test results:
| File name | Words | Analysed | Percentage |
|---|---|---|---|
| mlwiki-all-unique-words-00.txt | 199986 | 112281 | 56.14% |
| mlwiki-all-unique-words-01.txt | 199989 | 108650 | 54.33% |
| mlwiki-all-unique-words-02.txt | 199982 | 119577 | 59.79% |
| mlwiki-all-unique-words-03.txt | 199996 | 106705 | 53.35% |
| mlwiki-all-unique-words-04.txt | 199994 | 104216 | 52.11% |
| mlwiki-all-unique-words-05.txt | 199992 | 102098 | 51.05% |
| mlwiki-all-unique-words-06.txt | 105936 | 64755 | 61.13% |
| deshabhimani-all-unique-words.txt | 47821 | 34919 | 73.02% |
| 26.txt | 3481 | 2979 | 85.58% |
| 18.txt | 5696 | 4690 | 82.34% |
| 8.txt | 366 | 320 | 87.43% |
| 16.txt | 2043 | 1745 | 85.41% |
| 20.txt | 474 | 394 | 83.12% |
| 9.txt | 456 | 386 | 84.65% |
| 19.txt | 419 | 379 | 90.45% |
| 24.txt | 1402 | 1175 | 83.81% |
| 10.txt | 321 | 281 | 87.54% |
| 25.txt | 3657 | 3032 | 82.91% |
| 14.txt | 864 | 766 | 88.66% |
| 2.txt | 3666 | 3080 | 84.02% |
| 7.txt | 6627 | 5717 | 86.27% |
| 21.txt | 1561 | 1300 | 83.28% |
| 15.txt | 5805 | 5053 | 87.05% |
| 13.txt | 3705 | 3284 | 88.64% |
| 12.txt | 416 | 368 | 88.46% |
| 3.txt | 1843 | 1543 | 83.72% |
| 6.txt | 422 | 375 | 88.86% |
| 11.txt | 391 | 331 | 84.65% |
| 23.txt | 848 | 676 | 79.72% |
| 4.txt | 527 | 436 | 82.73% |
| 5.txt | 248 | 217 | 87.50% |
| 1.txt | 2026 | 1650 | 81.44% |
| 17.txt | 787 | 691 | 87.80% |
| 22.txt | 1010 | 855 | 84.65% |
| Total | 1402757 | 794924 | 56.67% |