SMC Newsletter: Jan-Feb 2025
SMC Domain Outage and Fix Our domain smc.org.in [https://smc.org.in/en/
മലയാളം ഫോണ്ടുകളും ചിത്രീകരണവും - ലേഖന പരമ്പരയിലെ പുതിയ ലേഖനം
സന്തോഷ് തോട്ടിങ്ങല്
ഭാര്യ, സൂര്യന്, കര്ത്താവു് തുടങ്ങിയ വാക്കുകളൊക്കെ ര് എന്നതിനു പകരം അക്ഷരങ്ങള്ക്കു മുകളില് കുത്തക്ഷരം ഇട്ടെഴുതുന്ന ശൈലി കണ്ടിട്ടുണ്ടാവുമല്ലോ. ര അടിസ്ഥാനമായ അക്ഷരമായതുകൊണ്ടും അക്ഷരങ്ങള്ക്കു മുകളില് കുറിപോലെ ഇടുന്നതുകൊണ്ടും ഗോപി രേഫം എന്ന പേരിതിനുണ്ടു്. കുത്തുരേഫം എന്നും വിളിക്കാം. ഇംഗ്ലീഷില് Dot Reph എന്നും പറയും.

ഈ അക്ഷരം ര് എന്നതിനു തുല്യമായ ഉച്ചാരണമാണെങ്കിലും യുണിക്കോഡ് സ്വന്തമായി കോഡ് പോയിന്റ് കൊടുത്തിട്ടുണ്ടു്. അതുകൊണ്ടുതന്നെ കര്ത്താവു്, കൎത്താവു് എന്നീ രണ്ടുവാക്കുകള് ഡേറ്റയില് വ്യത്യാസപ്പെട്ടിരിക്കുന്നു. ഡേറ്റയില് ഈ അക്ഷരം ഉച്ചരിക്കുന്ന പോലെത്തന്നെ വ്യഞ്ജനത്തിനു തൊട്ടുമുമ്പു് വരും. അഥര്വ്വം എന്നതു് അഥൎവ്വം എന്ന രീതിയില് എഴുതുമ്പോള് ഡേറ്റയില് അതു് താഴെപ്പറയുന്ന ക്രമത്തിലാണു്:
അ+ഥ+ ൎ + വ + ് + വ + ം
ഡേറ്റയെ അടിസ്ഥാനമാക്കി ഫോണ്ടുകള് ഉപയോഗിച്ചു് ലിപിയുടെ ചിത്രീകരണം സാധ്യമാക്കുന്നതു് ഷേപ്പിങ് എഞ്ചിനുകള് ആണു്. ഷേപ്പിങ് എഞ്ചിനുകള് ഇതു് ഡിസ്പ്ലേ ചെയ്യുന്നതു് പലരീതിയില് ആണ്. ഓപ്പണ്ടൈപ്പ് എന്ന സ്റ്റാന്ഡേഡ് ഇക്കാര്യത്തില് ഉണ്ടെങ്കിലും പ്രായോഗികമായി ആ സ്റ്റാന്ഡേഡിന്റെ നടപ്പാക്കലുകള് താഴെപ്പറയുന്ന കാരണങ്ങള് കൊണ്ടു് വ്യത്യസ്ത രീതിയില് പ്രവര്ത്തിച്ചേക്കാം:
ഇക്കാര്യത്തില് ഹാര്ഫ്ബസ് ആണു് സ്റ്റാന്ഡേഡനുസരിക്കുന്നതും പുതിയതും. ഹാര്ഫ്ബസ് എന്ന സ്വതന്ത്ര സോഫ്റ്റ്വെയര് ആണു്. ആന്ഡ്രോയിഡ്, ലിനക്സ്, ക്രോം, ഫയര്ഫോക്സ്, ലിബ്രെഓഫീസ്/ഓപ്പണ്ഓഫീസ് എന്നിവയിലൊക്കെ മലയാളം ചിത്രീകരിക്കുന്നതു് ഹാർഫ്ബസ് ഉപയോഗിച്ചാണു്.
ഹാര്ഫ്ബസ് ചെയ്യുന്നതു് ഇതാണു്: ആദ്യം, ഈ റെന്ഡര് ചെയ്യാന് കിട്ടിയ കോഡ്പോയിന്റുകളെ പുനഃക്രമീകരിക്കും. ആ സ്റ്റെപ്പുകള് താഴെക്കൊടുക്കുന്നു.
എന്തിനാണു് കുത്തു രേഫത്തിനെ വ-യ്ക്കപ്പുറം കൊണ്ടുപോയിട്ടതു് എന്നു ചോദിച്ചാല് സ്റ്റാന്ഡേഡിലങ്ങനെയാണെന്നേ ഉത്തരമുള്ളു. ഒരു മാര്ക്ക് (ചിഹ്നങ്ങള്, പൊതുവില്), അതു കഴിഞ്ഞുവരുന്ന ബേസ് ഡേറ്റയെ മാറ്റം വരുത്തുന്ന രീതി ഇന്ഡിക് ഷേപ്പിങ്ങില് കണ്ടിട്ടില്ല. സ്വരചിഹ്നങ്ങളും ്യ, ്ര, ്വ, ്ല, എന്നീ ചിഹ്നങ്ങളും ബേസ് ആയ വ്യഞ്ജനങ്ങള്ക്കു ശേഷമാണല്ലോ ഡേറ്റയിലും ഉള്ളതു്. മാര്ക്കുകള് ബേസിനു ശേഷം കൊണ്ടുവന്നു് പ്രൊസസ്സ് ചെയ്യുന്ന രീതിയിലേക്കു് കൊണ്ടുവരാനാണു് ഇങ്ങനെ ചെയ്യുന്നതെന്നനുമാനിക്കുന്നു.
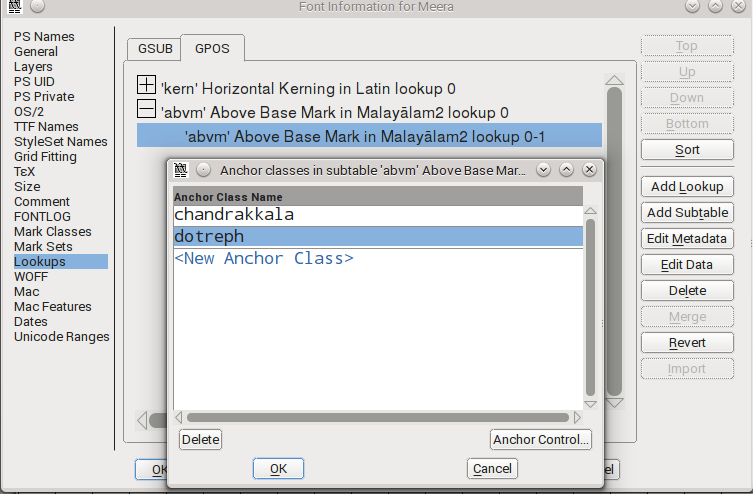
ഇപ്പോള് ഇനി ചെയ്യേണ്ടതു് കുത്തക്ഷരത്തിനെ വ്വയുടെ മുകളിലേക്ക് കൊണ്ടുവരലാണു്. അതിനായി കുത്തിനെ ഇടത്തോട്ട് നീക്കണം. ബേസില് നിന്നും മൈനസ് പൊസിഷനില് വരച്ചാലും മതി (ഒരു ഗ്രാഫ് പേപ്പറില് x<0 ആയ സ്ഥലത്തു് വരയ്ക്കുന്നതു് ഓര്ക്കുക).

ചിത്രത്തില് കാണിച്ചിരിക്കുന്ന പോലെ ഒരു നെഗറ്റീവ് ഓഫ്സെറ്റ് കൊടുത്താൽ തൊട്ടു മുന്പുള്ള അക്ഷരങ്ങളുടെ മുകളില് കയറി നില്ക്കുമെങ്കിലും ഈ ഓഫ്-സെറ്റ് ഒരു നിശ്ചിത സംഖ്യ ആയതുകൊണ്ടു് പല വീതിയിലുള്ള മലയാളം അക്ഷരങ്ങളുടെ കുത്തിടേണ്ട ഭാഗത്താവില്ല കുത്തുവരുന്നതു്. ക യുടെ കൃത്യം നടുക്കു് കുത്തു കൊണ്ടുവരാന് വേണ്ടി ഓഫ്സെറ്റ് നിശ്ചയിച്ചാല് ത്തയുടെ മുകളില് അതു് നടുക്കല്ല, വലത്തു ഭാഗത്താണു് വരിക. ഇതു് ഭംഗികേടാണു്. ഓരോ അക്ഷരത്തിനും കുത്തു് എവിടെ വരണമെന്നു കൃത്യമായി പറയാന് കഴിയണം. പൊതുവില് ഇതു് അക്ഷരങ്ങളുടെ നടുക്കു മുകള് ഭാഗത്താണെങ്കിലും എല്ലായ്പോഴും ആവണമെന്നില്ല.
ഈ പ്രശ്നം പരിഹരിക്കാന് മീര, രചന തുടങ്ങിയവയുടെ പഴയ പതിപ്പുകളില് ചെയ്തിരുന്നതു് കുത്തുരേഫമടങ്ങിയ ഗ്ളിഫുകള് പ്രത്യേകം ഫോണ്ടില് ചേര്ക്കലാണു്. അതായതു് ൎക, ൎഖ, ..ൎക്ക, ൎത്ത തുടങ്ങി എല്ലാം ചേര്ക്കുക. ഫോണ്ടിന്റെ വലിപ്പം കൂടുമെന്നതൊരു പ്രശ്നമാണു്. ക + ൎ എന്നതു് akhn നിയമപ്രകാരം ൎക എന്ന ലിഗേച്ചര് ഉണ്ടാക്കുക എന്നതായിരുന്നു നിയമം. akhn നിയമത്തിന്റെ ഒരു ദുരുപയോഗം കൂടിയായിരുന്നു ഇതു്. എല്ലാ ഓപ്പറേറ്റിങ് സിസ്റ്റങ്ങളിലും ഇതു് പ്രവര്ത്തിച്ചിരുന്നു.

കുറേക്കൂടി മെച്ചപ്പെട്ട ഒരു രീതി പിന്നീടു് ഞങ്ങള് കൊണ്ടുവരികയുണ്ടായി. ആങ്കര്പോയിന്റുകള് എന്ന ഒരു ആശയം ഉപയോഗിക്കലായിരുന്നു ആ വിദ്യ. പ്രത്യേകം ഗ്ളിഫുകള് വരയ്ക്കാതെ തന്നെ വേണ്ടിടത്തു് കുത്തുകള് കൊണ്ടുവരുന്ന വിദ്യ.
2013 ഓഗസ്റ്റില് ആണു് ഇതു ചെയ്യുന്നതു്. (https://github.com/smc/Meera/commit/fac6513e11b38eb65ede11d0c7e7e8db47c04836)
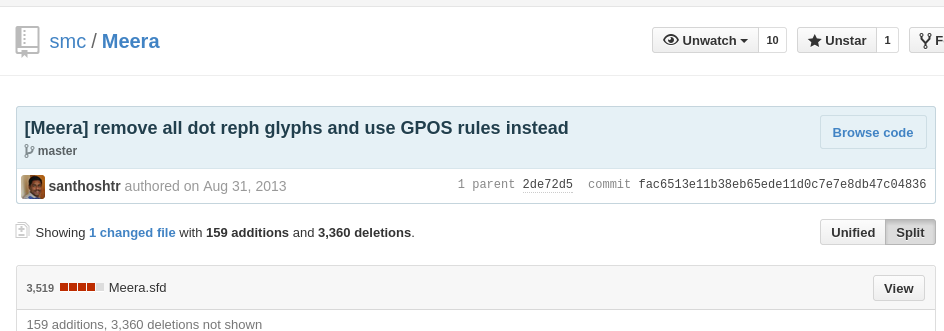
സബ്സ്റ്റിറ്റ്യൂഷന് നിയമങ്ങളും പൊസിഷനിങ് നിയമങ്ങളുമാണു് ഫോണ്ടിന്റെ ലുക്കപ്പ് ടേബിളില് എഴുതാന് സാധിക്കുന്നതു്. ഇവിടെ നമുക്ക് വേണ്ടതു് പൊസിഷനിങ് നിയമങ്ങളനുസരിച്ചുള്ള പ്രോഗ്രാമിങ്ങാണു്. ആപേക്ഷികമായി കുത്തുരേഫം എവിടെ വയ്ക്കാം എന്ന പ്രോഗ്രാമിങ്ങ് നിര്ദ്ദേശങ്ങള്. ഗ്ളിഫുകളുടെ പൊസിഷനിങ് നിര്ദ്ദേശങ്ങള് GPOS ടേബിളിലാണു് എഴുതുന്നതു്.
GPOS നിയമങ്ങളില് Above Base Mark വിഭാഗത്തിലാണു് കുത്തുരേഫത്തിന്റെ പ്രോഗ്രാമിങ്ങ് നിര്ദ്ദേശങ്ങള് വരുന്നതു്. ആങ്കര് പോയിന്റുകള് ഉപയോഗിച്ചാണു് ആപേക്ഷികമായി കുത്തക്ഷരം എന്ന മാര്ക്ക് ക്ലാസ് ഗ്ളിഫ് എവിടെ വയ്ക്കണം എന്നു തീരുമാനിക്കുന്നതു്.
ആങ്കര്പോയിന്റുകളെ മനസ്സിലാക്കാന് കാന്തവും ഇരുമ്പും എന്ന ആശയം ഉപയോഗിക്കാം.ൎച്ചഎന്ന ഉദാഹരണമെടുക്കുക. ച്ച എന്ന ഗ്ളിഫില് നമ്മള് ഒരു കാന്തം ഒട്ടിച്ചുവച്ചെന്നു കരുതുക. ച്ചയുടെ മുകളില് കുത്തക്ഷരം വരേണ്ട സ്ഥലത്തു തന്നെ ഇതു് ഒട്ടിച്ചെന്നു കരുതുക. കുത്തുരേഫത്തിന്റെ മുകളില് ഒരു ഇരുമ്പു കഷണം ഒട്ടിച്ചെന്നും കരുതുക. ച്ച കഴിഞ്ഞ്ൎവന്നാല് എന്തു സംഭവിക്കും? ഇരുമ്പു പതിച്ച കുത്തുരേഫം ച്ചയുടെ മുകളില് കാന്തം വച്ചിരിക്കുന്നിടത്തേയ്ക്ക് ചാടിപ്പിടിക്കും.

മീര, രചന തുടങ്ങിയ ഫോണ്ടുകളില് ആയിരത്തിലധികം ഗ്ളിഫുകളുണ്ടു്. ഈ ഗ്ളിഫുകള്ക്കെല്ലാം ആങ്കര്പോയിന്റുകള് ഇടണോ എന്നു ചോദിച്ചാല് അങ്ങനെ ഇടുകയാണെങ്കില് വളരെ നന്നായിരിക്കും എന്നാണു് ഉത്തരം. പക്ഷേ പ്രായോഗികമായി അങ്ങനെ എല്ലാ അക്ഷരങ്ങളുടെ മുകളിലും കുത്തുരേഫം വരില്ല. എന്നു മാത്രമല്ല, എല്ലാ അക്ഷരങ്ങളുടെ മുകളിലും ഈ പോയിന്റുകള് മാര്ക്കു ചെയ്യുന്നതേ മെനക്കേടുമാണു്.
ഒരു ഗ്ളിഫിന്റെ മുകളില് കുത്തുരേഫത്തിന്റെ ആങ്കര്പോയിന്റില്ലെങ്കില് എന്തു സംഭവിക്കും? ഉദാഹരണത്തിനു റ്റ എന്നതിനു നമ്മള് ആങ്കര്പോയിന്റൊന്നും ഇട്ടില്ല. റ്റ യുടെ മുകളില് കുത്തുരേഫം സാധാരണയായി കാണാറില്ല എന്ന ന്യായം വച്ചു്. പക്ഷേ ൎറ്റ എന്നു് ഒരാള് എഴുതിയാല് സംഭവിക്കുന്നതു് ഇതാണു്: ൎ + റ്റ എന്നതിനെ ഷേപ്പിങ് എഞ്ചിന് റ്റ + ൎ എന്നു മാറ്റും. ഇവ രണ്ടും അടുത്തുവന്നാല് ചെയ്യേണ്ട ഒരു പൊസിഷനിങ്ങ് നിയമവും ഇല്ലാത്തതിനാല് അവ അടുപ്പിച്ചടുപ്പിച്ചു വയ്ക്കും. കുത്തു രേഫത്തിനു നെഗറ്റീവ് ഓഫ്സെറ്റ് ആയതിനാല് അതു് റ്റയുടെ മുകളിലേയ്ക്ക് കയറി നില്ക്കും. മെച്ചപ്പെട്ട ഒരു fallback behavior ആണെന്നു പറയാം.
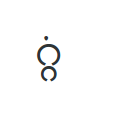
പക്ഷേ കഥ ഇവിടെ തീരുന്നില്ല. മുകളില് പറഞ്ഞതെല്ലാം ഹാര്ഫ്ബസ്സിനു മാത്രമേ ബാധകമാവുന്നുള്ളൂ. ഓപ്പണ് ടൈപ്പ് സ്പെസിഫിക്കേഷനില് കുത്തുരേഫത്തിന്റെ കാര്യത്തില് പ്രത്യേകിച്ചൊന്നും പറഞ്ഞിട്ടില്ല. മൈക്രോസോഫ്റ്റിന്റെ യുണിസ്ക്രൈബ് ചെയ്യുന്നതെന്തോ അതേ പോലെ ചെയ്യുകയാണു് ഹാര്ഫ്ബസ്സ് ചെയ്തിരിക്കുന്നതു്. പ്രായോഗികമായി താഴെപ്പറയുന്ന പ്രശ്നങ്ങള് ഉണ്ടു്.
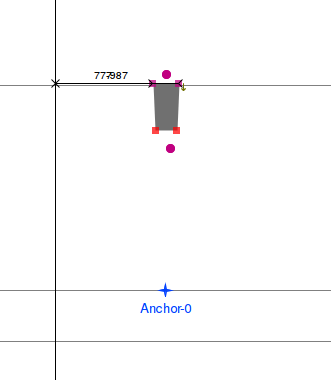
ഒന്നാമതായി, കുറച്ചു മുമ്പേ പറഞ്ഞ ൎറ്റ എന്നതില് സംഭവിക്കുന്ന കാര്യങ്ങള് അങ്ങനെ നടക്കണമെന്നില്ല. അവിടെ ഞാന് പറഞ്ഞു, ൎ, റ്റ എന്നിവയുടെ കോമ്പിനേഷനു പൊസിഷനിങ് നിയമങ്ങള് ഇല്ലാത്തതിനാല് അവ അടുത്തടുത്തിരുന്നു് കുത്തുരേഫം റ്റയുടെ മുകളില് കയറിയിരിക്കുമെന്നു്. പക്ഷേ ഇവിടെ റ്റ ഗ്ലിഫില് ആങ്കര്പോയിന്റൊന്നും ഇല്ലെങ്കിലും, കുത്തുരേഫത്തിന്റെ ഗ്ളിഫില് ആങ്കര് പോയിന്റുണ്ടല്ലോ. കാന്തവും ഇരുമ്പും ഉദാഹരണം എടുക്കുകയാണെങ്കില് ഇവിടെ കാന്തം ഇല്ല. പക്ഷേ ഇരുമ്പുണ്ടു്. കാന്തമില്ലാതെ ഇരുമ്പെങ്ങോട്ടും പോവില്ല. പക്ഷേ ആപ്പിളിന്റെ റെൻഡറിങ് എഞ്ചിനുകള് കാന്തമില്ലെങ്കില്, കാന്തം 0 പൊസിഷനില് ഉണ്ടെന്നു വയ്ക്കും. അതായതു് റ്റയുടെ കാര്യത്തില് റ്റയുടെ ഇടത്തേ അറ്റത്തു് മുകളില് കുത്തുരേഫം കൊണ്ടുപോയി ഇടും.
രണ്ടാമതായി, ൎ + റ്റ എന്നതു് റ്റ+ ൎ എന്ന ക്രമത്തിലാക്കിയാണു് റെൻഡറിങ് എന്നു പറഞ്ഞു. അങ്ങനെ ചെയ്യാന് ഷേപ്പിങ് എഞ്ചിനു മനസ്സില്ലെങ്കിലോ? ആപ്പിളിന്റെ ഷേപ്പിങ് എഞ്ചിനങ്ങനെ ചെയ്യാന് മനസ്സില്ല. അപ്പോള് [കുത്തുരേഫം][റ്റ] എന്നിങ്ങനെ അടുത്തുവെയ്ക്കും. കുത്തുരേഫത്തിനു നെഗറ്റീവ് ഓഫ്സെറ്റ് ഉള്ളതിനാല് അതു് വീണ്ടും ഇടത്തോട്ട് ചാടി അതിന്റെ ഇടത്തുള്ള അക്ഷരത്തിന്റെ മുകളില് പോയി കിടക്കും.
കെ.ഡി.ഇ യില് ഉപയോഗിക്കുന്ന Qt യുടെ (ക്യൂട്ട് എന്നാണു് വായിക്കേണ്ടതു്) ഷേപ്പിങ് എഞ്ചിനും മുകളില് പറഞ്ഞ പണി ഒപ്പിക്കും. Qt 5.0 മുതല് അതു് ഹാര്ഫ്ബസ്സ് ഉപയോഗിക്കുന്നതിനാല് ഈ പ്രശ്നം ഉണ്ടാവില്ല. എങ്കിലും, ഏറ്റവും പുതിയ ഓപ്പറേറ്റിങ് സിസ്റ്റം മാത്രമല്ലല്ലോ ആളുകള് ഉപയോഗിക്കുക.
ഗൂഗിളിന്റെ നോട്ടോ സാന്സ് മലയാളം ഫോണ്ടു് മുകളില് പറഞ്ഞ പ്രശ്നങ്ങളെ എല്ലാം കൈകാര്യം ചെയ്യുന്നതു് താഴെപ്പറയുന്ന രീതിലാണു്:
ഈ രണ്ടുകാര്യങ്ങള് ചെയ്യുന്നതുകൊണ്ടു് കുത്തക്ഷരത്തിന്റെ ക്രമം മാറുമോ ഇല്ലയോ എന്നതു് നോട്ടോസാന്സ് മലയാളത്തിനു പ്രശ്നമല്ല. ഈ രീതി മീര, രചന തുടങ്ങിയ നമ്മുടെ ഫോണ്ടുകളിലും ചെയ്യേണ്ടിവരുമെന്നു തോന്നുന്നു, എല്ലാ ഓപ്പറേറ്റിങ്ങ് സിസ്റ്റങ്ങളിലും കുത്തക്ഷരം നേരെ കാണാന്.
ഇവിടെയും കുത്തക്ഷരത്തിന്റെ കഥ തീരുന്നില്ല. ൎത്തോ - എന്നതില് എന്തു സംഭവിയ്കുന്നുവെന്നു നോക്കുക.
ൎത്തോ = ൎ + ത + ് + ത + ോ
= ൎ + ത + ് + ത + േ + ാ (Normalization- canonical decomposition)
= ൎ + ത്ത + േ + ാ (akhn )
= േ + ത്ത + ൎ + ാ (reordering)
= േ + ൎത്ത+ ാ
= ൎത്തോ
ഇവിടെ ഫൈനല് റെൻഡറിങ് ശരിയാണു്. പക്ഷേ വൎത്തുളം, അൎജ്ജുനന്, നിൎഗ്ഗുണം തുടങ്ങിയ വാക്കുകള് നോക്കുക. കുത്തുരേഫത്തോടൊപ്പം സ്വര ചിഹ്നങ്ങള് കൂടി വരുന്നുണ്ടവയില്. ആ സ്വരചിഹ്നങ്ങളാവട്ടെ, അടിസ്ഥാനാക്ഷരത്തെ മാറ്റുന്നുമുണ്ടു്.
ൎത്തു എന്നതു് ൎ + ത + ് + ത + ു ആണു്. ഇതില് ത + ് + ത എന്നതു് akhn നിയമമനുസരിച്ചു് ആദ്യമേ ത്ത ആയി മാറും. അപ്പോള് നമുക്ക് ൎ + ത്ത + ു എന്ന ശ്രേണി കിട്ടി. ഇനിയാണ് റീഓര്ഡറിങ്ങ് നടക്കുന്നതു് (നടക്കുമെങ്കില്).
ത്ത+ ൎ + ു എന്നു വരും. ആദ്യത്തെ രണ്ടെണ്ണമെടുത്തു് ൎത്ത എന്നാക്കി മാറുമ്പോള്, ൎത്ത + ു ബാക്കിയായി. ത്ത+ ു = ത്തു എന്ന നിയമം അറിയാമെങ്കിലും കുത്തക്ഷരത്തോടു കൂടിയ ൎത്ത യ്ക്ക് ഉകാരം ചേര്ന്നാല് എന്തു ചെയ്യണമെന്നു പിടിയില്ലാത്തതിനാല് ൎത്തു എന്ന റെന്ഡറിങ്ങിലേക്ക് എത്തിച്ചേരുന്നു. അങ്ങനെ പഴയ ലിപി ഫോണ്ടു് ഉകാരം വേര്പെട്ട പുതിയ ലിപി ഫോണ്ടു് ആയിത്തീരുന്നു!
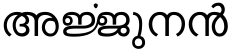
ഷേപ്പിങ് എഞ്ചിന് അതിന്റെ ഉള്ളില് ചെയ്യുന്നതെന്തു് എന്നു മനസ്സിലായില്ലെങ്കില് ഈ വക പ്രശ്നങ്ങള് പരിഹരിക്കാന് പറ്റില്ല. ഹാര്ഫ്ബസ്സ് വളരെ സങ്കീര്ണമായ ഷേപ്പിങ്ങ് എഞ്ചിനാണു്. അതു് ഫോണ്ടുകള് ഡീബഗ്ഗ് ചെയ്യാന് പ്രത്യേകം ഒരു സഹായവും ചെയ്യുന്നില്ല. ആകെയുള്ളതു് ഹാര്ഫ്ബസ്സിന്റെ കൂടെ വരുന്ന hb-shape എന്ന യൂട്ടിലിറ്റിയാണു്. അതുപയോഗിച്ച് ഫൈനല് റെന്ഡറിങ്ങിനു് ഏതൊക്കെ ഗ്ളിഫുകളാണു് ഉപയോഗിച്ചതെന്നു മനസ്സിലാക്കാം

ഈ ചിത്രം പറയുന്നതിതാണു്. ൎജ്ജു എന്നു റെന്ഡര് ചെയ്യാന് , ജ്ജ 0 മുതല് 2753 പോയിന്റുവരെ സ്ഥലമെടുത്തു. അതിനു ശേഷം കുത്തുരേഫമാണു് എടുത്തതു്. ഓര്ക്കുക, ഇവിടെ ഉകാരമായിരുന്നു നമുക്ക് വേണ്ടിയിരുന്നതു്.കുത്തുരേഫം നെഗറ്റീവ് 723 പോയിന്റ് ഒന്നാമത്തെ ഗ്ളിഫിനുമുകളില് കയറ്റിവച്ചു. പിന്നെ വെറുതെ ഉകാരചിഹ്നം ഇട്ടു. അതിനു് 639 പോയിന്റെടുത്തു.
2013 സെപ്റ്റംബറില് സുരേഷ് സുറുമ, രജീഷ് എന്നിവര് ഈ പ്രശ്നം ഹാര്ഫ്ബസ്സ് മെയിലിങ്ങ് ലിസ്റ്റില് ഉന്നയിച്ചു. അവിടെ നിന്നു കിട്ടിയ നിര്ദ്ദേശങ്ങളുടെ അടിസ്ഥാനത്തില് മാര്ക്ക് ക്ലാസ് എന്ന ഒരാശയത്തിന്റെ പുറത്തു് ഇതു് പരിഹരിച്ചു. അതു് താഴെ വിശദമാക്കുന്നു.
മാര്ക്ക് ക്ലാസുകള് ചിത്രീകരണ നിയമങ്ങളെ സംബന്ധിച്ചുള്ള ചില നിബന്ധനകള് പറയാനുള്ള മാര്ഗമാണു്. കുറച്ചു ഗ്ലിഫുകളുടെ ഒരു കൂട്ടമാണു് മാര്ക്ക് ക്ലാസ്. ഈ ഗ്ലിഫുകളെല്ലാം മാര്ക്ക് ടൈപ്പാവുകയും ചെയ്യും. മലയാളത്തിനെ സംബന്ധിച്ചിടത്തോളം സ്വര ചിഹ്നങ്ങള്, ചന്ദ്രക്കല, കുത്തുരേഫം എന്നിവ മാര്ക്ക് ടൈപ്പ് ആണു്. ഒരു ചിത്രീകരണ നിര്ദ്ദേശത്തിന്റെ കൂടെ ആ പ്രോഗ്രാമിങ്ങ് നിര്ദ്ദേശം നടപ്പിലാക്കുമ്പോള് പരിഗണിക്കേണ്ട ഇത്തരം ഗ്ലിഫുകളെ അവയുടെ ക്ലാസിന്റെ പേരു കൊടുത്തു് അടയാളപ്പെടുത്താം.
നമുക്കിവിടെ വേണ്ടതു് കുത്തുരേഫം സബ്സ്റ്റിറ്റ്യൂഷന് നിയമങ്ങളുടെ പ്രൊസസ്സില് പങ്കെടുക്കാതെ വിട്ടുനില്ക്കലാണു്. ത്തയുടെയും ഉകാരത്തിന്റെ ഇടയില് നിന്നാലും ത്തു ഉണ്ടാവുന്നതിനു് അതു് തടസ്സമാവരുതു്. ത്ത + ു ചേര്ന്നു് ത്തു ഉണ്ടാകുന്ന നിയമങ്ങള് psts ഗണത്തിലാണു് വരുന്നതു്. psts നടക്കുമ്പോള് ഇടയില് കുത്തുരേഫം വന്നാലും അതിനെ അവഗണിച്ചു് ത്തു ഉണ്ടാകണം.
അതിനര്ത്ഥം ഈ psts ന്റെ കൂടെ കുത്തുരേഫം ഇല്ലാത്ത ഒരു മാര്ക്ക് ക്ലാസ് പറയണം. നമുക്കതിനെ nomark എന്ന ഒരു പേരിട്ട് നിര്വചിക്കാം.
ഈ ക്ലാസില് കുത്തുരേഫം പാടില്ല എന്നു പറഞ്ഞുകഴിഞ്ഞല്ലോ. കാരണം ഈ ക്ലാസില് ഉള്ള ഗ്ലിഫുകളെ ചിത്രീകരണ നിയമത്തില് പങ്കെടുപ്പിക്കും.
പിന്നെ ഏതൊക്കെ ഗ്ലിഫുകളാണു് നമുക്കിതില് വേണ്ടതു്? ഏതൊക്കെ മാര്ക്ക് ക്ലാസുകളെയാണു് psts ല് നമുക്ക് പങ്കെടുപ്പിക്കേണ്ടതു്? അങ്ങനെ പ്രത്യേകിച്ചു് ഒരു ഗ്ലിഫും നമുക്കു് ആവശ്യമില്ല. അപ്പോള് ഈ ക്ലാസില് ഒന്നുമില്ലാതാവില്ലേ? അതെ. ഈ ക്ലാസില് ഒരു ഗ്ലിഫും ഇല്ല.
psts അധിഷ്ഠിത നിര്ദ്ദേശത്തിന്റെ നിര്വ്വചനത്തിന്റെ കൂടെ നമ്മള് ഈ nomark എന്നു പേരുള്ള ക്ലാസ് മാര്ക്ക് ക്ലാസ് ആയി ചേര്ത്തു.
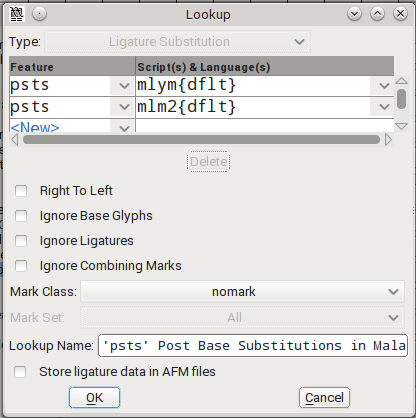
അതോടുകൂടി ൎത്തു -വിന്റെ ചിത്രീകരണം ശരിയായി വരുകയും ഉകാരം വേര്പെട്ടു നില്ക്കാതെ ത്തയോടു ചേര്ന്നു നില്ക്കുകയും ചെയ്യും.
ഈ ആശയം ഒന്നുകൂടി മനസ്സിലാക്കാന് ഫോണ്ട് ഫോര്ജിന്റെ ഡോക്യുമെന്റേഷനിലുള്ള വിവരണം താഴെക്കൊടുക്കുന്നു.
In many lookups it is important to be able to ignore some mark glyphs, but not others. For example when forming an arabic ligature, the vowel marks are (usually) irrelevant to the ligature and you would want to ignore all marks. In situations where you are positioning marks on a base glyph you might in one case, want to ignore all marks that position on top of the glyph while paying attention to those underneath it. And then in another lookup, the reverse might be true.
അറബിയില് എഴുതുമ്പോള് സ്വരചിഹ്നങ്ങള് വാക്കിന്റെ എഴുത്തു തീര്ന്ന ശേഷം ആണു് ഇടുന്നതു്. വരയുടെ ഒഴുക്ക് സ്വരചിഹ്നങ്ങള് മുറിക്കുന്നില്ല. കുത്തുരേഫവും ലിഗേച്ചര് ഫോമേഷനെ ബാധിക്കരുതു് എന്നാണല്ലോ അൎജ്ജുനന് എന്ന ഉദാഹരണത്തില് നമ്മള് കണ്ടതു്.
രേഫത്തിന്റെ ചിത്രീകരണത്തിന്റെ സാങ്കേതികവശങ്ങള് തത്കാലം ഇവിടെ നിര്ത്തുകയാണു്. ര് ചില്ലിന്റെ കാര്യം മറ്റു ചില്ലക്ഷരങ്ങളുടെ കൂടെ വിശദീകരിക്കാം. മറ്റുള്ള അക്ഷരങ്ങളുടെ ചിത്രീകരണം അടുത്ത അദ്ധ്യായങ്ങളില് ചര്ച്ച ചെയ്യാം.
ഈ പരമ്പരയിലെ മുന്ലേഖനങ്ങള്