SMC Newsletter: Jan-Feb 2025
SMC Domain Outage and Fix Our domain smc.org.in [https://smc.org.in/en/
This was originally written by Santhosh Thottingal and published at Thottingal.in.
The Bureau of Indian Standards(BIS) had published a Part of Speech(POS) tagset for Indian languages. POS is the process of assigning a part of speech marker to each word in a given text. In this article, I am reviewing the tag set defined in it. While developing mlmorph project I had explored a candidate POS tagging schema for Malayalam. I did not choose BIS tagset for the reasons I am going to explian in this article. Along with the tagset, we will also analyse the ILCI-II Malayalam text corpus published by TDIL using the BIS POS tagset. I will start with some of the concepts and how that applies to different languages.
Identifying the part of speech, or the grammatical category of the word is one of the fundamental requirement for higher level analysis of text. In a sentence “She lives at Palakkad”, identifying ‘she’ as a pronoun, ‘lives’ as verb with a specific tense, Palakkad as a Proper noun, specifically as a place name is crucial to understand the semantics of the text. There are rule based and statistical approaches for identifying these categories. We will not discuss those methods in this article, but once that identification is done, the result is the text with each word annotated with a tag. For example, here is a POS tagged sentence in English:
There/EX are/VBP 70/CD children/NNS there/RB
Here, EX, VBP, CD, NNS, RB are POS tags. Specifically, these are tags defined in PENN treebank POS tags. It has 45-tags, used to label many corpora in English.
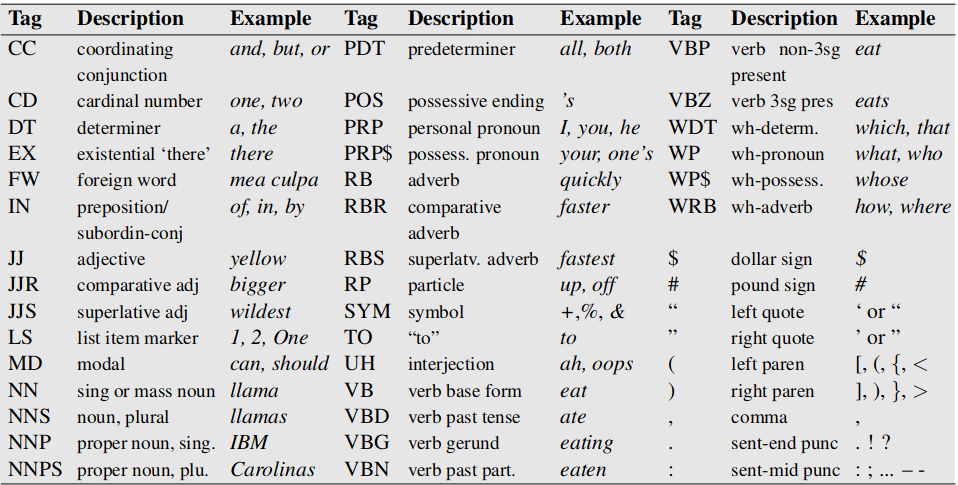
There are alternate tagsets such as Brown tagset, which defines 87 tags for English. The members of the tagset is defined based on language characteristics and how detailed analysis is required. For example, In Penn tagset IN is used for both subordinating conjunction like if, when, unless, after and prepositions like in, on, after. A different tagset may define separate tags for them, so that it would be possible to differentiate them.
Languages with rich morphology require a more complex tagging scheme and methods. Malayalam is one such language, so is many of the dravidian languages, Turkish, Hungarian, Finnish, Czech and many others. A rich morphology language has more information in a word compared to languages like English. If the word is agglutinated and inflected, it has multiple words and inflection information. Since POS tagging is the basis for higher level information processing, extracting as much information as possible from the word is important.
To understand the productive word formation in a morphologically rich language, compared to English, a corpora analysis can be used. A 250,000 word token corpus of Hungarian has more than twice as many word types as a similarly sized corpus of English (Oravecz and Dienes, 2002). A 10 million word corpus of Turkish has 4 times unique words compared to similarly sized English corpus(Hakkani-T ̈ur et al., 2002). A 10 million word corpus of Malayalam has 14 times unique words compared to similarly sized English corpus, as calcualted from SMC Corpus. LanguageCorpus sizeUnique words English10 million97,734 Turkish10 million4,17,775 Malayalam10 million14,27,392
In English, lot of information about the syntactic function of a word is represented by word order or neighborimg function words. For example in the phrase at Palakkad the word at and its word order in the sentence gives the place name Palakkad its locative inflection. If we consider the same word in Malayalam, പാലക്കാട്ടിൽ, the word പാലക്കാട് is inflected(locative) and contains the whole information. Identifying പാലക്കാട്ടിൽ just as Proper noun is not sufficient. The nominal inflection, that is is locative here, should also be identified.
For this reason, the tagging system for agglutinative, inflective languages uses a sophisticated tagging system and has bigger tag set larger than the 50-100 tags we have seen for English. The general practice is to use a sequence of tags rather than a single primitive tag. An example from (Hakkani-T ̈ur et al., 2002):
A morphology analyser is used for this tagging. The tag set for these languages are huge. In such a morphologically analysed and tagged MULTEXT-East corpora in English, Czech, Estonian, Hungarian, Romanian, and Slovene(Dimitrova et al, 1998; Erjavec 2004, Hajic, 2000) gives the following tagset size Languagetagset size English139 Czech970 Estonian476 Hungarian401 Romanian486 Slovene1033
The Universal Dependencies project which defines 16 POS tags and an extensive feature tags to tag any language is worth mentioning here. Mlmorph uses the tagset from Universal Dependencies.
Mlmorph uses the sequence based tag set. Currently there are 87 tags - you can refer it here: https://gitlab.com/smc/mlmorph/blob/master/tags.jsonA word പാലക്കാട്ടിൽ will be analysed as പാലക്കാട്<np><locative>. Similarly തിരുവനന്തപുരവുമാണ് will be tagged as തിരുവനന്തപുരം<np>ഉം<cnj>ആണ്<aff>. As you can see we are extracting maximum information out of the words for higher level processing. The number of unique pos tag sequences is not finite.
The BIS pos tagset attempts to define a common tagset for all Indian languages. I will focus on Malayalam language here, but the tagset is mostly same for other languages too. The tags are defined in 11 categories.
അക്കാര്യം, ഇക്കാര്യം, അക്കാണുമ്മാമലയൊന്നും shows that demonstrative prefixing. The document does not discuss them.നീലത്താമര -here നീല is adjective to താമര- a perfect case you need sequence of POS tags as we discussed earlier. A related characterestics of Malayalam - coordinatives(ദ്വന്ദസമാസം) is missed here. For example, in the word അച്ചനമ്മമാർ - here it is tricky to avoid interpreting അച്ഛൻ as adjective of അമ്മ.In general BIS tag set is incomplete for Malayalam. It is more obvious from the example tagging given in the same document.

Now I will attempt to prove my observation by actually using a corpus that is tagged using the above tag system and provided by TDIL.
Under the Indian Languages Corpora Initiative phase –II (ILCI Phase-II) project, initiated by the MeitY, Govt. of India, Jawaharlal Nehru University, New Delhi had collected monolingual corpus in Malayalam. This is the final outcome of the project and there are approx. 31,000 sentences of general domain. It uses the BIS tag system. This corpus is available in TDIL website to download, but it is not straight forward. To download the complete corpus, you need to register in the site and fill a form, sign and send the physical copy by post to TDIL to get download link. The corpus has very restrictive terms of use. You can only use it for research. The same site also provide a sample version of corpus which has about 30% of original corpus. For my analysis, I used that smaller version.
Let us take a tagged sentence for analysis:
YACD54 കരീമിന്റെ\N_NNP `\RD_PUNC പറയാന്\N_NNP ബാക്കിവെച്ചത്\N_NNP
`\RD_PUNC ,\RD_PUNC അനില്\N_NNP തോമസിന്റെ\N_NNP
`\RD_PUNC മരം\N_NNP പെയ്യുമ്പോള്\N_NNP `\RD_PUNC എന്നിവ\N_NN
പ്രദര്ശനത്തിന്\N_NN തയ്യാറായി\RB നില്ക്കുന്നു\V_VM_VF .\RD_PUNC
The above sentence is from mal_art and culture_set1.txt in the corpus. YACD54 is sentence Id.
If I understood correctly this is a mannually tagged corpus. And as we see, excluding punctuations, I would say 3 out of 11 words are tagged almost correctly- അനിൽ, തയ്യാറായി, നില്ക്കുന്നു.
I will list a few more samples for your analysis.
MYGD42 വാല്മീകി\N_NNP രാമായണത്തിലും\N_NNP ഭാസന്റെ\N_NNP കൃതികളിലും\N_NN
എല്ലാം\QT_QTF ഇവിടുത്തെ\N_NST പർവ്വതങ്ങളെ\N_NN പരാമർശിച്ചിരിക്കുന്നതു\V_VM_VNF
കാണാം\V_VM_VNF .\RD_PUNC
MYLTD52 പായ\N_NN കെട്ടിയ\JJ വലിയ\JJ വഞ്ചികളും\N_NN മീന്\N_NN പിടിക്കുന്ന\V_VM_VNF
കൊച്ചുതോണികളും\N_NN പോകാന്\V_VM_VNF തുടങ്ങും\V_VM_VNF .\RD_PUNC
Malayalam is a morphologically rich language and require sequence based POS tagging system with wide set of POS tags and Feature tags. A smaller POS tagging system like BIS POS tagging system does not address the language characteristics. The POS tag set itself is incomplete and not prepared with details. Using such a tag system will miss most of the important POS information required for higher level processing. The tagging examples given in the POS tag document and the corpus provided by TDIL are full mistakes and make me wonder whether it went through any review at all. I would not advice to use that corpus for any statistical training purpose or any reference purpose.
Even though I used Malayalam language as example, the BIS tag set has same tags for other languages as well. I would argue that those languages also face more or less same issues I explained in this article.
Thanks for reading!