SMC Newsletter: Jan-Feb 2025
SMC Domain Outage and Fix Our domain smc.org.in [https://smc.org.in/en/
This was originally written by Santhosh Thottingal and published at Thottingal.in.
On July 10,2019 ICANN released Label generation rules for eight scripts Devanagari, Gurmukhi, Gujarati, Kannada, Malayalam. Oriya, Tamil, Telugu. These rules are criteria for determining valid Domain Names for the Root Zone of the Domain Name System (DNS).
The Internet Corporation for Assigned Names and Numbers (ICANN) is a non-profit organization which takes care of the whole internet domain name system and registration process. Internationalized Top Level Domain Names are domain names not limited to English. These scripts were approved as candidates for domain names in 2016. I had written an article introducing it in a pevious blog post.
For these script Neo-Brahmi Generation panel was formed and was responsible for defining the script rules that make a valid domain name. I was a volunteer member of the panel.
A root zone in DNS corresponds to the top level domains. The DNS root zone is served by thirteen root server clusters(a.root-servers.net to m.root-servers.net) which are authoritative for queries to the top-level domains of the Internet. While initializing a DNS service, very name resolution either starts with a query to a root server or uses information that was once obtained from a root server.
Initially it used to have only the well known TLDs like .com and then later latin country codes such as .in, .us, .uk etc. In November 2009, ICANN decided to allow these domain name strings in the script used in countries. So “.in” should be able to represent in Indian languages too. They are called Internationalized country code Top Level Domain names, abbreviated as IDN ccTLD.
You can see the actual record at a root server: http://www.internic.net/domain/root.zone. Along with popular top level domains, you can see new domains like .design, .google, .city, .aero, .club, .cleaning etc. A few International domain names are also present there. For example .भारत, the IDN ccTLD for India in devanagari script is present there. Search for “xn–h2brj9c” which is the Punycode for भारत. Similarly .ഭാരതം(Punycode: xn–rvc1e0am3e), the ccTLD for India in Malayalam script is also present there.
IDN ccTLDs were approved in a fast track process. But for general domain names in Root Zone, a standard that defines what is a valid string that can be a root zone label had to be defined. This is called label generation rules. Its usage is illustrated in the image below:
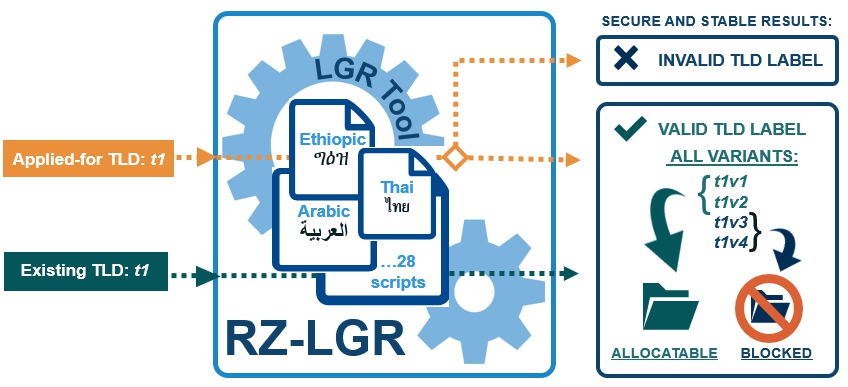
Root Zone Label Generation Rules Version 3 (RZ-LGR-3) is now available, covering the following sixteen scripts: Arabic, Devanagari, Ethiopic, Georgian, Gujarati, Gurmukhi, Hebrew, Kannada, Khmer, Lao, Malayalam, Oriya, Sinhala, Tamil, Telugu, and Thai scripts.
For Malayalam, Veena Solomon was leading the effort. I too helped. The document is available at https://www.icann.org/sites/default/files/lgr/lgr-3-malayalam-script-10jul19-en.html
Basically, it lists all allowed unicode characters in a domain string. Archaic characters are not allowed. Control characters like ZWNJ, ZWJ are not allowed. Detailed clarification on the use of confusable sequences such as ള്ള(ള+ള) vs ള്ള(ള്+ള) and ററ(റ+റ) vs റ്റ(റ്+റ) is provided.